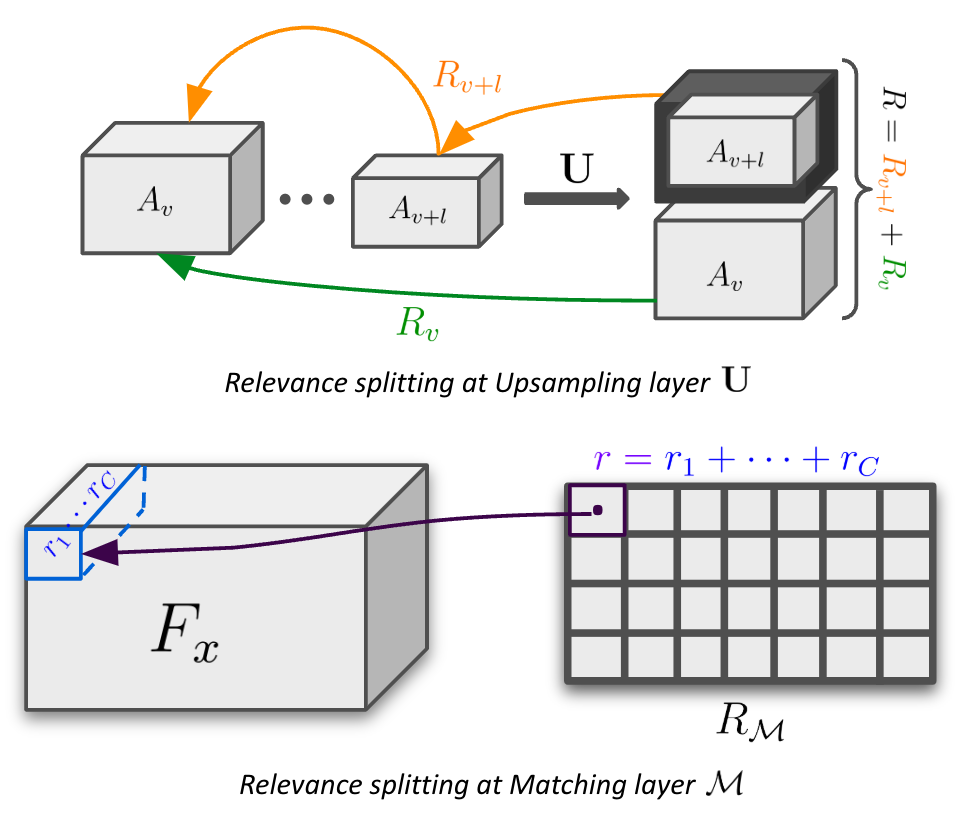
Figure 1. We introduce CAVE - Concept Aware Volumes for Explanations. Left: We learn 3D object volumes, here cuboids, with concept representations. Each concept captures distinct local features of objects. Right: At inference, these concepts are matched with 2D image features, achieving robust and interpretable image classification.